

近日,以“软件定义存储未来”为题的首届软件定义存储峰会在深圳召开。中国移动苏州研发中心高级软件开发工程师郭建楠分享了《Ceph在中国移动的大规模应用实践》。郭建楠从Ceph在中国移动的应用、分布式块存储实践、分布式对象存储实践以及生产实践对Ceph的期望四个部分进行阐释。

以下为演讲文字整理:
各位嘉宾下午好!很荣幸参加DOIT主办的SDSS峰会,我是郭建楠,来自中国移动苏州研发中心,今天给大家带来的分享题目是Ceph在中国移动大规模应用实践。
首先跟大家介绍一下Ceph在中国移动的应用情况,第二、第三章节介绍分布式块和对象的实践,针对我们生产实践和运维过程中碰到的问题以及对Ceph的期待跟大家做分享,主要是体现Ceph在场景化中可能面临的和急需解决的问题。

中移苏州软件技术有限公司是中国移动全资子公司,注册资本7亿,我Base在云技术产品部,主要做一些云计算标准化、定制化的产品、解决方案,承接云计算的软硬件的集成服务和技术支撑,也可以做一些云计算相关应用的云化迁移。存储团队分为四个研发方向:块、对象、文件、数据库存储。前面三个基于软件定义存储做的,最后的数据库场景是我们最近才开始的,主要提供一体机的解决方案。
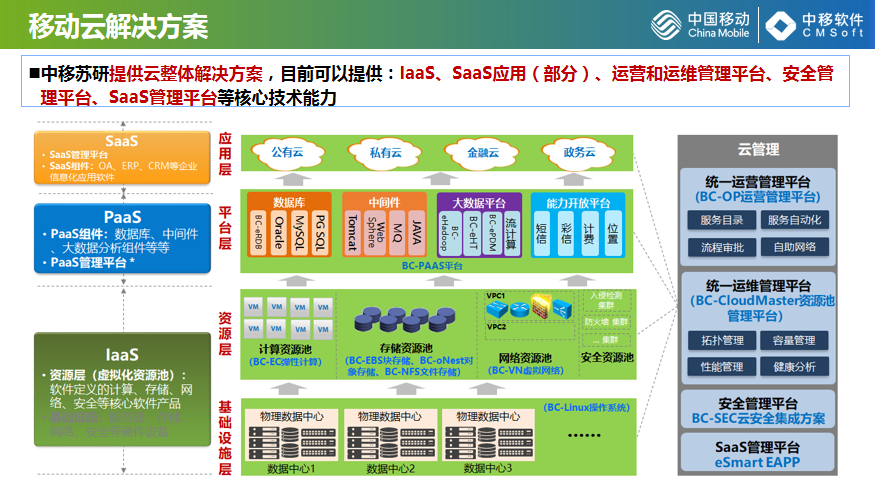
这是移动云整体的解决方案,我们可以提供IaaS、SaaS应用,还可以做一些统一的运营、运维的管理平台以及安全管理平台,承载的业务可以按公有云、私有云、金融云、政务云进行区分。
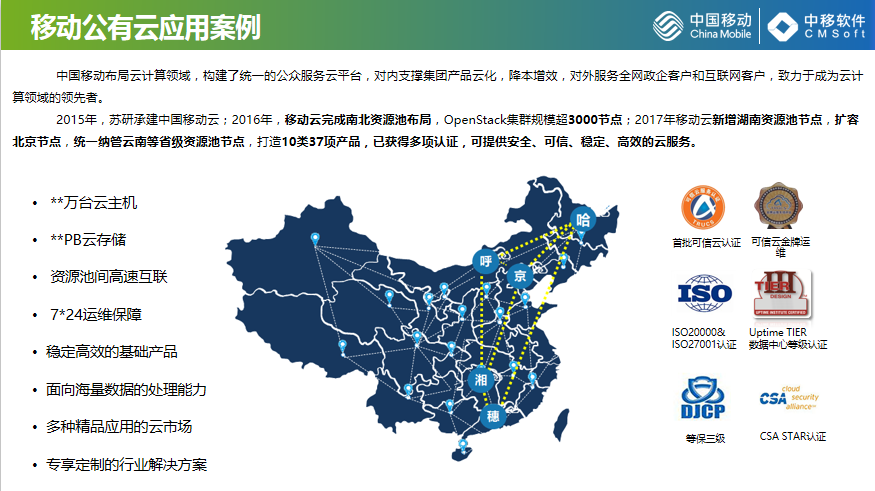
以一个具体的案例看一下,这是我们移动自己的公有云的建设情况,2015年开始中国移动集团规划公众服务云的平台,对内打造自己产品的云化,达到降本增效的目的。对外服务于全网的政企客户和互联网用户。2015年我们开始承建移动云,最早是在中国移动的南方基地开放资源池,2016年在北京信息港实现资源池的布局,实现南北资源池的布局。2017年在湖南的长沙、内蒙古的呼和浩特、黑龙江的哈尔滨实现多节点的部署,后续纳管各省级的资源池,建设规模涉及虚机10万台。
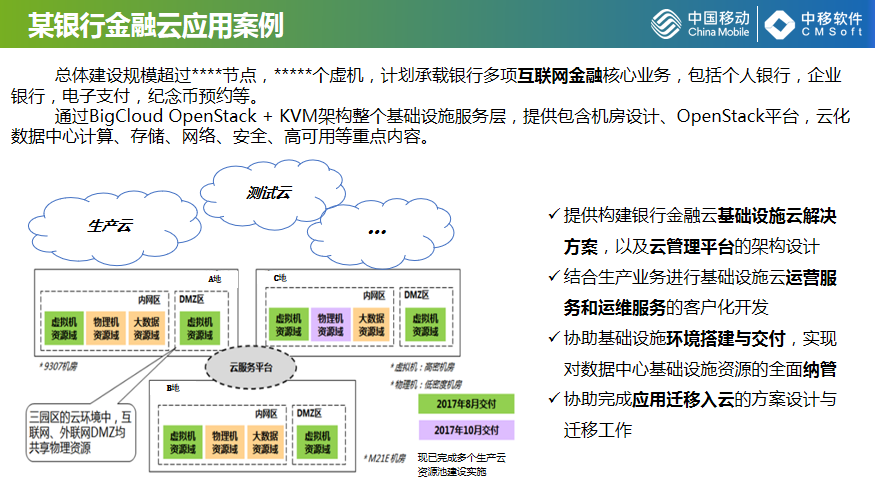
在服务移动内部客户的同时,我们也会为外部客户承建部分的基础设施,如为某国有银行做的金融云案例,总的建设规模超过1500个节点,虚机涉及3万个左右,上海、北京两地三中心的生产环境,承载该银行个人网银、企业网人、电子支付、纪念币预约等互联网应用。除了生态云,也为他们承接了测试云和开发云,OpenStack平台十几套,现在达到一共40套的规模。

聚焦到云产品,主要在软件定义方面块存储、文件存储、对象存储,存储方案选型也是基于开源做的,块是基于Ceph。我们在选型开源产品的同时也积极的回馈社区,在Ceph全版本过程中,中国移动贡献国内排名第三,全球排名13位。虽然做存储的团队不多,但也想尽一份力量,把开发的功能尽可能的回馈社区。

我自己是做研发的,有些涉及细节,这幅图是逻辑架构图,引擎层是基于Ceph开源方案直接应用块构建,总体来说Ceph确实是一款非常优秀的开源软件,可以提供丰富、稳定的功能。我们可以直接拿来使用,不光是这些,在生产上确实不够,我们也可以做一些周边的工作,可以建SSD,也在做一些兼容性的验证。磁盘控制器和磁盘的错误检查,网卡的检测、SSD的寿命监控,都是生产上需要的功能。服务层结合一些业务场景,开发一些特性,Ceph现在基于QEMU的热迁移功能。除了QEMU,我们也可以使用NBD对接开发,也可以用ISCSI。除了这之外,右边还是展示了我们自己的管理平台,可视化的方式可以进行资源的监控、性能监控、集群的再现滚动升级和在线扩容。
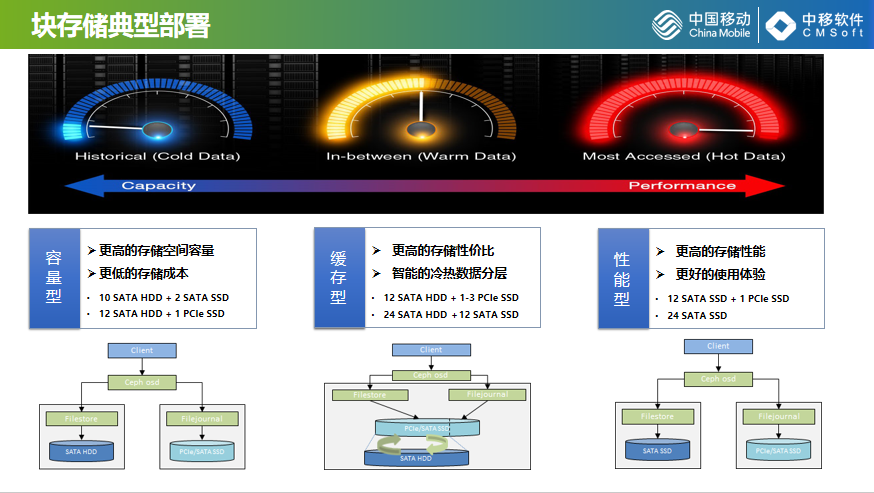
Ceph在块存储方面,在移动的部署方式。我们知道数据是有热度的,频繁访问我们称为热数据,它需要存储性能。访问低一点的是冷数据,需要的存储容量更节约存储成本,我们把生产环境的Ceph集群分为三类:容量型、缓存型、性能型。容量型是更低的存储成本,更大的存储容量,性能型更好的存储体验和更高的存储性能,缓存型介于两者之间,实现更高的存储性价比。上面列出了一些典型的配置,主要是依据中国移动集团的服务器系集采,中国移动的服务器是有集中采购的,一般是在里面进行选型,比如说缓存型、性能型的,我们选择性不大,基于现有的典型配置,我们梳理出一些可行的方案,一般控制在3%。缓存型把缓存比控制在13%左右,性能型就是上面的SSID。
下面是三种模式的抽象、概要的树图,容量型和性能型比较简单,我们现在生产上批量推的还是Filestore,它还要跟普通的HDD进行绑定形成一个逻辑设备,构成具备缓存功能的逻辑盘。
再介绍下缓存方案,缓存简单来说就是为了实现数据的冷热迁移,我们用小容量的、高性能的SSD承载频繁访问的热点数据,用机械盘承载访问频次比较低的数据达到性能和成本的均衡,逻辑上的抽象概念就是右边这幅图,这套方案怎么读写SSD、HDD,数据在SSD和HDD之间怎么迁移。
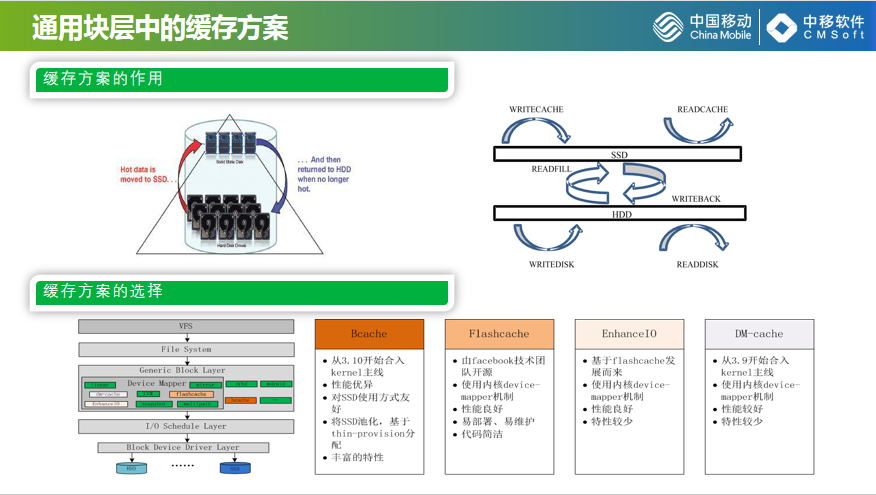
左下角是LinuxIO的路径图,上面是虚拟文件系统、通用块到驱动再到最终的设备,调动层、驱动层再到设备层,我们说的缓存方案一般集中在通用块层,通用块层有很多开源可以借鉴的项目,Google开源的Bcache、Facebook的开源flashcache,Enhance,我们对flashcache进行调研,就是把HDD的存储空间按块划成SSD,做成数据的冷热管理。效果图比较直观,数据性能比较高,基本上可以达到SSID的性。
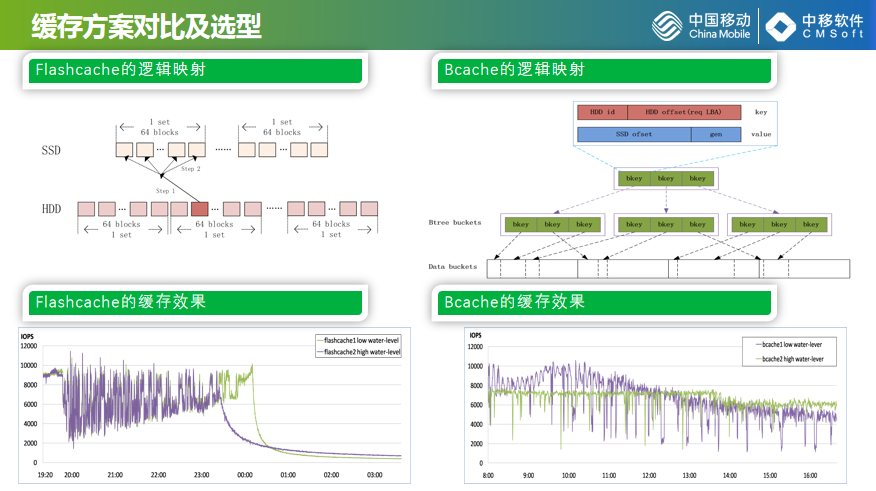
右边是Bcache的模式,使用B数和B+数的明显,B+数的夜节点是BIO,每个IO的请求根据访问进行排序,因为它使用的B+数,其实有一个指针可以达到迅速的连起来,对于数据的索引会特别方便,可以把它依照我们HDD的文件算法一次就达到尽量多的刷下去,这也是缓存的优势、特性。Bcache的缓存效果比flashcache更优秀一些,它的性能有比较高的输出,即使写满了,也可以直接回归到HDD盘的性能,是有小幅下降,还是有很好的加速效果。
flashcache和Bcache在现网有具体的使用,Bcache我们想作为主推的方案,对于Bcache也做了很多的优化,它在做性能匹配输出的时候还有很多的毛刺,尤其是几根比较长的,像针一样的插在下面,就是Bcache的影响,我们也是改变了算法,让曲线更加的平缓输出。

块存储的典型部署场景,我们知道Ceph在四、五年迅速进入大家的视野,OPENSTACK新的组件主要是提供卷,除了OPENSTACK以外,我们也充分发挥云接口的特性,可以把它产品化,可以提供虚拟化的对接,虽然Ceph方案比较曲折,我们也是两套方案都在做,目前在LinuxIO的投入比较大,现在还有一些小的问题需要后续优化改善,中国移动做了很多的工作,帮助方案进行落地。

对象存储,基于OPENSTACKSwift,文件的结构以NFS、CFS的接口,经过负载均衡把请求发到RGW,社区的存储引擎包括两种,基于典型的部署方案指导,我们对部署方案进行了一些实例化,负载均衡是有RVS,引擎层我们把数据类似于刚才块的缓存一样,也是做了存储池之间的缓存,对象上传的时候加了一个标签,是访问频度较高还是较低,多少天之后会转变访问频次较低的存储,对象上传的时候指定热度和生命周期,访问频次比较高就会放在副本的存储池比较高效,访问频次比较低就着存储放在纠删码的存储池。上传有生命周期的概念,把到达生命周期副本池的数据迁移到纠删码的存储池,热点数据的性能和冷存储数据的存储成本得到兼顾和均衡。
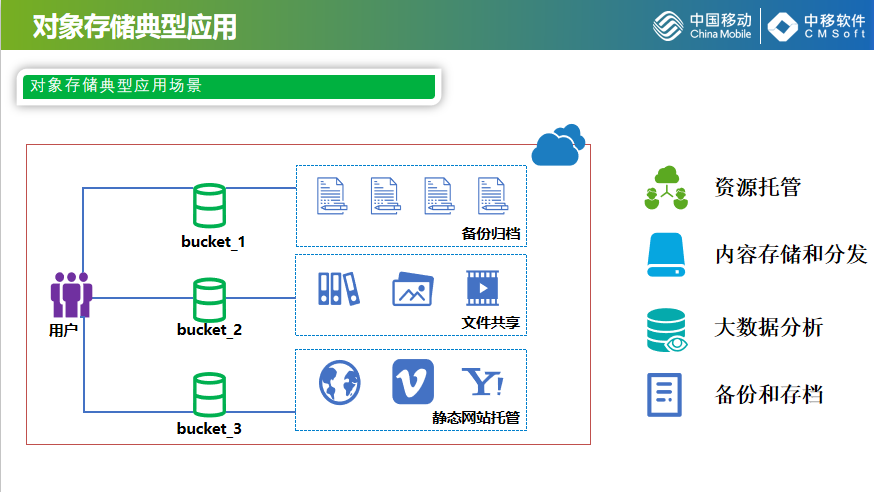
这个是对象存储的应用场景,对象存储和OPENSTACK结合不是那么紧密,它也是有了存储的池化,我们对象存储主要是应用于文件共享、静态网站的托管、备份归档,我们也形成解决方案做CDN后端的数据持久化存储。
我们使用Ceph也是有两年左右的时间,我们2016年转型使用Ceph,对于生产实践中也碰到一些问题,对于Ceph也有一些期望。我们列了一些问题,并不是说Ceph不好,Ceph是作为开源的软件,它的正常运行要求有比较稳定、比较健康的硬件环境。Ceph本身也做了很多的边界条件的处理,我们生产端也遇到一些问题,Ceph目前是没法处理的,这些逻辑不太适合做到Ceph中,如果有做Ceph产品化的公司我们达到分享的目的。

硬件故障比例的问题,主要是网络磁盘,完整的故障Ceph都能处理,主要是一些极个别故障和亚健康的故障,我们知道Ceph对于一个节点网络是有一个机制的,可以通过仲裁机制进行集群,我们碰到一个集群是这样的,两台服务器的集群不通,这两个节点互相报对方离线了,收到这个信息以后一人一票不能根据节点的方式PK掉,影响了集群的正常使用,辅助存储管理人做故障的排查。
服务器网卡丢包,亚健康监控要有,这些不一定够,奇葩的问题,机柜有堆叠交换机,光模块出现光衰弱,影响范围是这两台交换机下面所有的存储服务器的网卡都是偶发性的丢包、使用高,导致两个机柜下的结点OSD时而DOWN,时而UP,这一类也是比较典型的问题。磁盘类的故障,坏扇区,磁盘厂商对偶尔两个坏扇区不认为是什么问题,在我们的实践来看,实际上是写时触发的,对这个坏块进行再次写之前,对它的读操作一直会出现异常,这个异常包括可能读不出来,可能读得不完整,可能读得速度相当慢,都会导致集群使用上的异常,而且集群还会伴随Ceph在IO访问时告警。我们通过告警输出查一下有没有坏块,如果有及时提醒管理人关注或是换盘。
慢速磁盘,也遇到很多,慢的程度不一样,几十兆、几兆、几十K的都有,生产上总结下来不能应对所有的慢盘故障,要有Ceph周边管理平台做一些监控。还有一类比较诡异的是Raid卡故障,Raid卡是磁盘连接到服务器的一种方式这也是我们遇到的故障,比如说这个故障是我们运维某银行双11保障全天存储运行正常,晚上11点左右这个集群的时延,每七分钟冲高一次,系统的ROBS和带宽没有明显的业务压力变化,我们也是排查了将近几个小时,最后从Raid卡里导出每七分钟出现一次,和集群冲高刚好对应上,这类的问题更容易做到Ceph里,如果是HDA卡、Raid卡,涉及到监控列表的问题,如果是产品化,这是要在管理系统外围的方式上做一些强化,否则这个Ceph集群像演讲中说的,没有降落伞的保障,遇到这些问题比较难排查。
我们对Ceph的期望,备份容灾的能力,耿航先生说了,存储可以实现多数据中心的源数据和数据的同步功能,块的这块虽然也有应用的功能,实测下来看比较难取舍,如果用的话安全性会高一点,性能下降得也比较多。对于Ceph的问题、期望总结如上。
中国移动的苏研代表中国移动在今年成为Ceph基金会全球首批顶级会员,我们会尽我们的力量助力Ceph开源技术产品化,我的分享就是这些,谢谢大家!